The agentic autonomous defense fabric — building an AI-native SOC
An interconnected operating model for autonomous SOC, self-healing detections, policy-aware defense, and continuous production protection.
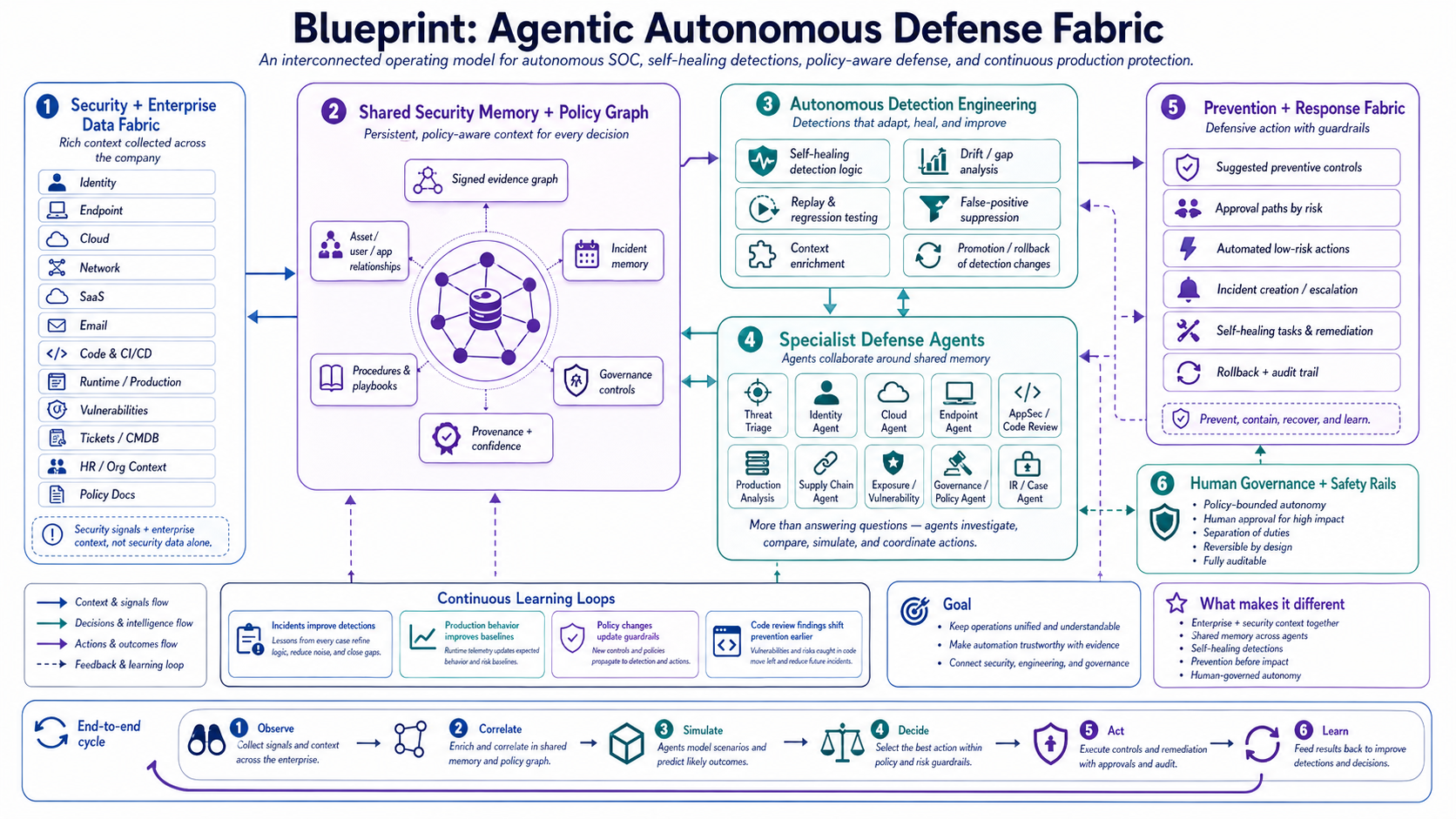
The SOC of the next five years will not look like a row of analysts staring at dashboards. It will look like a fabric of cooperating AI agents — each specialized, each accountable, each connected through shared memory and policy. This is the blueprint for that shift.
Why agentic, why now
Three forces converge to make agentic defense the right architecture right now. First, the data volume in modern security telemetry exceeds human capacity to triage at the speed attackers move — measured in seconds, not hours. Second, large language models have become competent enough at structured reasoning that they can perform the correlation and enrichment work that consumed most of an analyst's day. Third, the operational pattern of multiple cooperating specialist agents — each narrow, each tested, each replaceable — is maturing into a deployable engineering discipline.
The agentic defense fabric is not one model. It is many models, each with a role, sharing memory and policy, governed by humans who set the rules and review the outcomes.
The security and enterprise data fabric
Every agent in the fabric draws from the same foundation: a unified data fabric covering endpoint, identity, network, cloud, email, EDR/XDR, vulnerability data, threat intel, and tickets. The fabric is not a data warehouse — it is a queryable abstraction over your existing sources, indexed for the kinds of questions agents need to ask.
The principle is the same federated SecOps thesis behind platforms like Vega's SAM: do not move the data, push intelligence to where it lives. Agents query the fabric, not a centralized store. This keeps cost down, latency low, and avoids the brittleness of yet another ETL pipeline.
Shared agent memory and policy graph
What separates a fabric from a collection of bots is shared state. The shared memory layer holds three classes of information: persistent context and prior episodes (what has this agent learned about this environment over time), the policy graph (what is allowed, what requires approval, what is forbidden), and signal evidence cache (deduplicated, enriched indicators with confidence scores).
When an agent makes a decision, it cites memory. When memory changes, it is auditable. When a policy is updated, every agent sees the new version. This is the difference between AI that learns from itself and AI that drifts unpredictably.
Autonomous detection engineering
The first specialist agent in the fabric is the detection engineering loop. It observes false positive rates, replay-tests rules against historical data, proposes promotion or retirement of detections, and generates new candidate rules from threat intel.
The agent does not deploy detections autonomously. It produces a pull request — with the proposed rule, the test results, the expected coverage, and the predicted noise impact. A human reviews it. But the work of writing, testing, and tuning detections — work that consumes most of a senior detection engineer's week — happens overnight.
The operational gain is not just speed. It is consistency. Detection quality stops being tied to which engineer happened to write the rule.
Specialist defense agents
The fabric runs many specialist agents in parallel, each scoped narrowly:
Triage agent — initial alert classification, deduplication, severity scoring. Reads from the shared evidence cache, writes to the case queue.
Enrichment agent — pulls context from identity, asset, vuln, and threat intel sources. Attaches it to the case without analyst intervention.
Investigation agent — runs pivot queries (lateral movement, beaconing patterns, persistence indicators), produces a structured timeline, suggests next questions.
Containment agent — proposes containment actions (isolate host, revoke session, block IP) with human approval required by default.
Reporting agent — produces incident summaries in the format the customer or regulator expects.
Each agent is small, single-purpose, and replaceable. If a model improves, you swap that agent without rebuilding the fabric.
Prevention and response fabric
Detection is half the job. The other half is closing the loop with prevention and response.
The response fabric integrates with the controls that already exist in your environment — EDR for endpoint actions, IAM for identity revocations, network controls for blocking, ticketing systems for escalation. Agents do not replace these tools. They orchestrate them.
The prevention loop is more subtle: agents observe what attacks were blocked, what almost worked, and what patterns are emerging. That observation feeds back into the detection engineering agent (write a rule for next time), the policy graph (tighten this control), and the vulnerability management workflow (this CVE is being actively exploited in your environment, prioritize the patch).
Human governance and safety rails
The most important component of the fabric is the one that is easiest to underbuild: human governance. Every agentic system needs explicit boundaries around what agents can do without approval, what requires sign-off, and what is forbidden entirely.
The governance layer enforces four things. Action allow-lists: containment is allowed for low-severity isolated workstations, requires approval for production systems, forbidden for the CEO's laptop. Audit trails: every agent action, every memory write, every policy evaluation is logged with attribution. Kill switches: humans can halt the fabric instantly, scoped to a single agent or globally. Continuous evaluation: a separate eval harness replays historical incidents and measures whether the fabric handles them better, worse, or the same as the human baseline.
This is not optional infrastructure. It is what makes the fabric trustworthy enough to deploy in production.
Continuous learning loops
The fabric improves over time through three feedback loops. The fast loop: alert quality scores from triage update the detection agent's priorities within hours. The medium loop: weekly retro on cases the fabric handled poorly produces new test cases and policy refinements. The slow loop: quarterly model updates incorporate new threat patterns, new tools, and new operating conventions.
The goal is not autonomy for its own sake. The goal is that the senior humans on the team spend their time on the cases that matter — the novel threats, the strategic decisions, the cross-org coordination — while the fabric handles the volume.
What to build first
Do not try to build the whole fabric at once. The pattern that works: pick one agent, give it one job, prove it works, then expand.
Most teams start with the triage agent because the value is immediate (alert volume drops, analyst burnout improves) and the risk is low (worst case, you still have humans triaging). The detection engineering agent comes second because it produces auditable artifacts (pull requests) that fit existing review workflows. The investigation agent comes later, after the foundation of memory and policy is mature.
The specialist agents and full response loop are not the place to start. They are where you end up after 12-18 months of disciplined, governed deployment of the earlier pieces.